

A while back I wrote a post about one of the most popular graph based planning algorithms, Dijkstra’s Algorithm, which would explore a graph and find the shortest path from a starting node to an ending node. I also explored the very fundamentals of graph theory, graph representations as data structures (see octrees), and finally, a python implementation that animates the search process for several example graphs. If you haven’t read that yet, I urge you to please check that out, because I will be continuing the discussion assuming some prior knowledge with the subject.
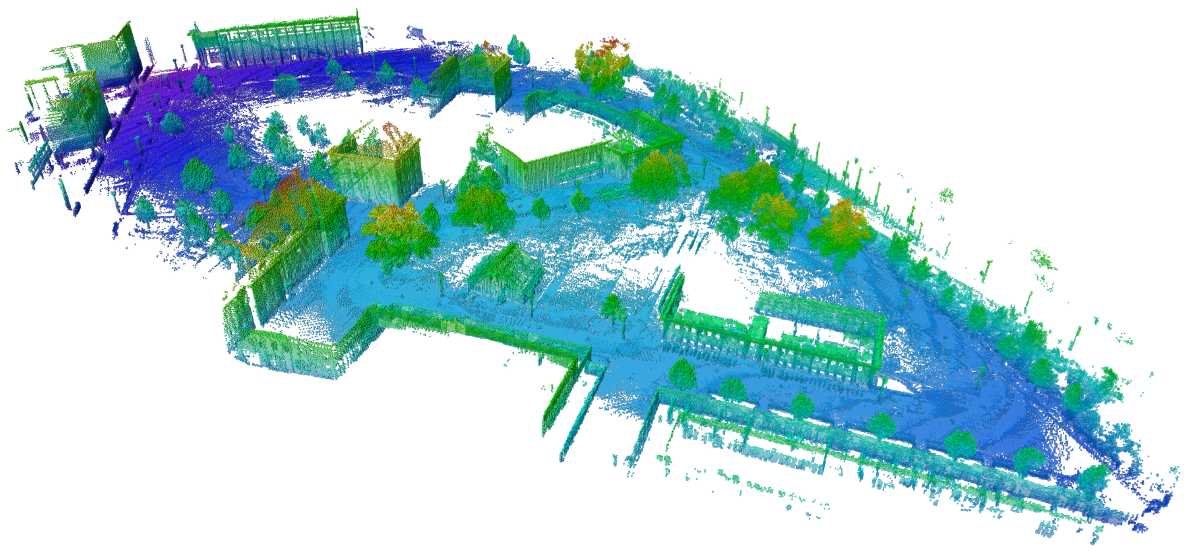
An example octomap of an outdoor environment. A map this large can be visualized efficiently thanks to the tree-based structure of an Octomap. Source: octomap.github.io/freiburg_outdoor_big.png
Dijkstra vs A*
Dijkstra is novel because it begins exploring from a starting node and continues until it reaches the ending node. It then identifies the list of nodes that connect the end node to the start as one single path. This means that Dijkstra works by exploring nodes in order based by their distance from the starting node. To put it another way, this means that it will equally explore nodes that are farther from the goal as well as nodes closest to the goal as it expands outwards from the starting node. As one can imagine, that can become computationally expensive as our graph representation of our world grows.
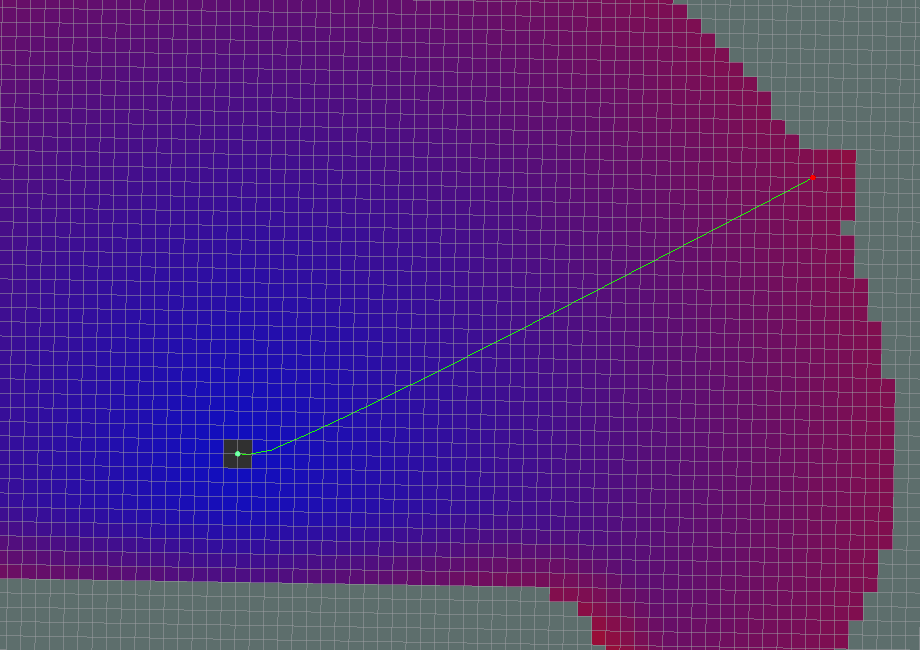
Example of Dijkstra’s Algorithm attempting to go from a start node to a goal node. See how it has to expand out almost the entire distance of the path in every direction before it finds the goal? Source: wiki.ros.org/global_planner
So, in 1968, an AI researcher by the name of Nils Nilsson tried to improve on this planning approach for Shakey the Robot, a prototype mobile robot from SRI. The algorithm that was developed for Shakey is what is now known as A* (pronounced ‘A Star’). A* tries to improve on Dijkstra’s Algorithm by focusing only on exploring nodes that bring us closer to our goal. This greatly improves our speed of finding the shortest and most direct path.
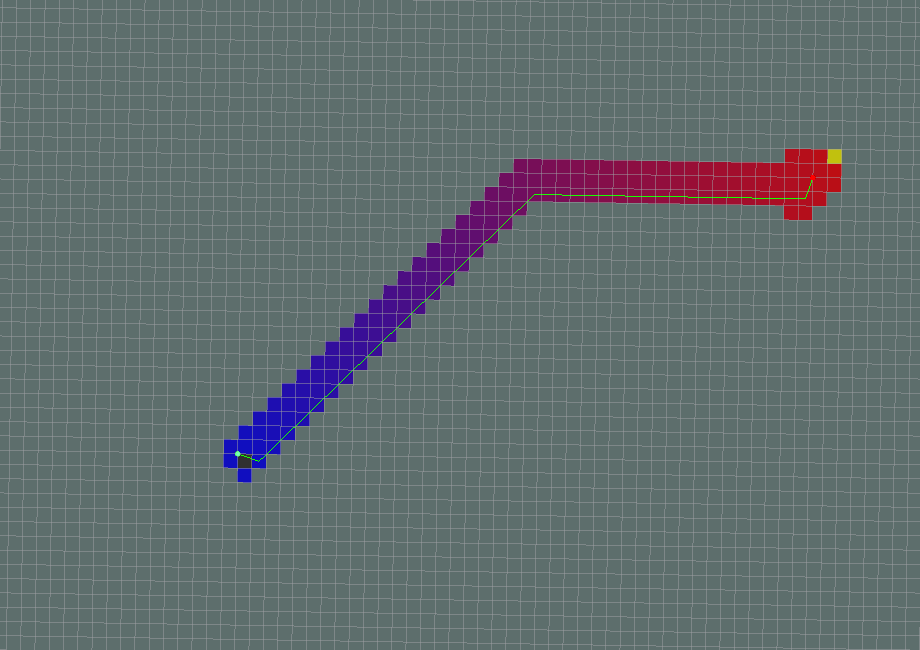
The same path planning problem as shown above, but look at how quickly the goal is found? With the use of some forcing heuristic, we ensure that we only expand nodes that drive us towards the goal node. Source: wiki.ros.org/global_planner
The way A* does this is via the introduction of a heuristic function that guides the node expansion towards the goal. Our heuristic functions will be used to create a correlation from every node in the graph to a non-negative cost value. Heuristic functions (represented as the function H below) must satisfy two basic criteria:
- H(goal) = 0
- For any two adjacent nodes x and y:
- H(x) <= H(y) +d(x, y)
- d(x, y) = weight/length of edge from x to y
The notion that our cost is zero at the goal node helps address the issue described above that when we explore from the starting node, we have no real direction. So if we have some extra value that can assess if an explored node will bring us closer to the goal, we improve our search time. Following these two criteria, we can ensure that every node will be less than or equal to the length of the shortest path from node n to the goal. Two of the most popular examples of heuristics are the Euclidean Distance, and Manhattan Distance from any node, n, in the graph to the goal, g, in the graph. We can, therefore, say, given any node, n, at (xₙ, yₙ) and a goal, g, at (xg, yg):
- Euclidian Distance
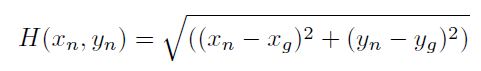
- Manhattan Distance

With this heuristic now in place, we can update our previous Dijkstra algorithm as follows:
For each node, n, in the graph:n.distance = Infinity, n.g = Infinity
Create an empty liststart.distance = 0start.f=H(start)add start to list
While list not empty:Let current = node in the list with the smallest f value, remove current from listIf (current == goal) return SuccessFor each node, n that is adjacent to current:if n.g > (current.g + cost of edge from n to currentn.g= current.g+ cost of edge from n to currentn.f = n.g + H(n)n.parent = currentAdd n to list if it is not there already
A* Python Example
In keeping with my previous post on Dijkstra’s Algorithm, I have written a quick Python example to illustrate the above algorithm.
To get started, let’s clone the repo locally on your machine:
$ git clone https://github.com/atomoclast/realitybytes_blogposts.git
With that cloned locally, you should be able to run it by navigating to:
../realitybytes_blogposts/pathplanning/
and running:
$ python a_star.py
You should see a window open up similar to the one below showing an occupancy map. The darker blue color is free space, the lighter blues are walls/obstacles. The yellow square is the starting node, and the orange square is the goal node. You will see that we will begin searching around the starting node. Once a node is searched, it will become aqua blue, and the search will keep radiating out until the goal node is found. Once that is found, the shortest path is calculated and visualized in red.

A* Algorithm in action for an Occupancy Map. It will search until the goal is found, then visualize the path in red.
In the above example, there is a large L shaped wall that would prevent the quick expansion of a Dijkstra approach. That method would have to wrap around the wall and search nearly the entire map before it found the goal. Alternatively, our A* searches grow towards the goal until it is reached, with very little concern for nodes that take us away from the ending node.
In the example map code, you can see that we define a test_grid variable as a list of lists where ‘0’ indicates an open node and ‘1’ indicates an obstacle:
test_grid = [[0, 0, 0, 0, 0, 0],
[0, 1, 1, 1, 1, 0],
[0, 1, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 1, 0, 0, 1, 0]]
We then define the start and end nodes as a list of [x, y] node positions (starting from 0). Using this basic format, you can challenge yourself to create different maps to test your A* Algorithms.
Another interesting thing is our heuristic function, which will calculate how far each node is on the graph from our goal node. For a map this size, calculating the cost from the goal to each surrounding node costs very little, but for larger robotic applications, it makes more sense to calculate the heuristic at every iteration of the loop for computational efficiency.
What makes this A* implementation especially intriguing is the way we handle the heuristic value in our loop. As shown below:
for i in range(len(delta)):
x2 = x + delta[i][0]
y2 = y + delta[i][1]
if len(self.grid) > x2 >= 0 <= y2 < len(self.grid[0]):
if closed[x2][y2] == 0 and self.grid[x2][y2] == 0:
g2 = g + cost
f = g2 + self.heuristic[x2][y2]
open.append([f, g2, x2, y2])
closed[x2][y2] = 1
delta_tracker[x2][y2] = i
In this loop, we will search through every possible orthogonal direction, and then calculate the f value as described in the pseudo-code above, which is just the running cost + the heuristic cost. Once our cost is found for the explored node, we add it to a running list of possible “open” nodes from which we pick the lowest f value on the next iteration, thus bringing us closer to the goal.
That’s it. That’s what makes A* such an amazing yet powerful algorithm!
Where to go from here:
If you are still curious about playing with some code, I challenge you to upgrade my Dijkstra’s code to A*, since I decided to go a different route with my example.
If you want to look at other examples of A* in Python, check out Python Robotics’ A* Example.
A* ROS Example
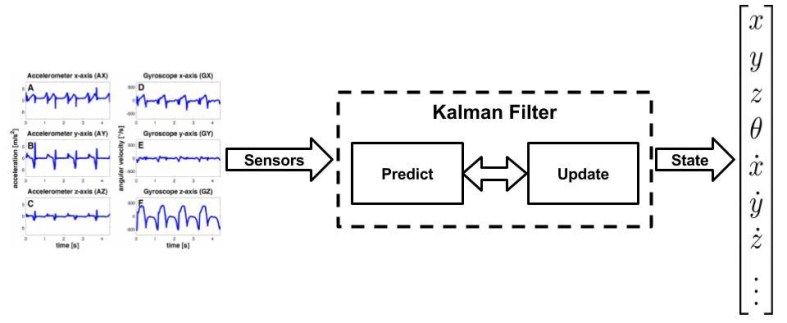
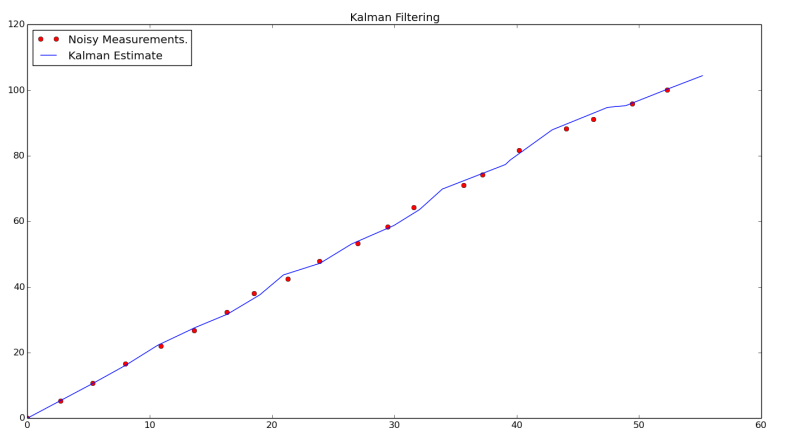
The ROS Navigation Stack is a set of software packages that make path planning and motion control (more on this in a coming post) as simple as possible for differential drive and holonomic wheeled mobile robots. There are multiple packages in this stack to help with everything from building up Cost Maps with costmap_2d to localization with packages such as amcl, which is an adaptive Monte Carlo Localization approach. Monte Carlo Localization is the process of using a known map and sensor measurements to localize where a robot is with a high degree of confidence using something called particle filters (see my other post about Kalman Filters for some motivation on the state estimation problem, PFs are just another type of filter). The most pertinent portion of the stack for Grid-Based path planning will be the global_planner package.

Source: wiki.ros.org/navigation?action=AttachFIle&do=get&target=nave_comic.png
global_planner
This package uses an implementation of A* for a fast, interpolated global planner for navigation via a discretized map. There are other implementations like a traditional Dijkstra planner that are available for configuration during launch, but the A* is undoubtedly faster.
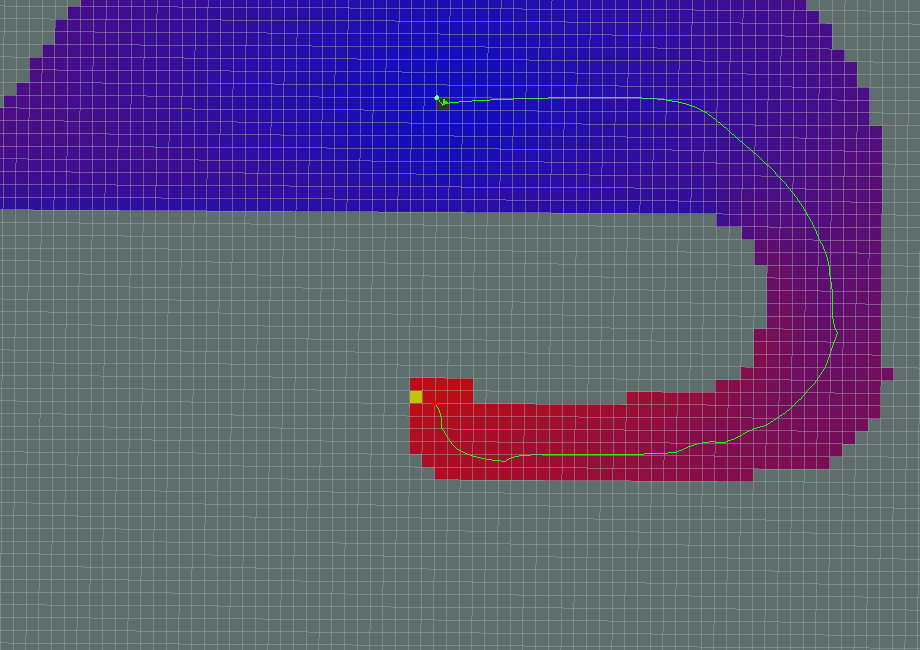
Example A* path. Source: http://wiki.ros.org/global_planner?distro=melodic
While this provides a high-level plan through a map, the question remains of how the robot’s base frame must be controlled taking into account local obstacles such as corners of walls and stand-alone objects. The move_base package provides such a feature. Once the global planner searches and publishes a plan, this package will then take that plan and link the global/local planners with an actual controller. Below is a graphic showing how the move_base node subscribes and publishes to various topics for a differential wheel robot.
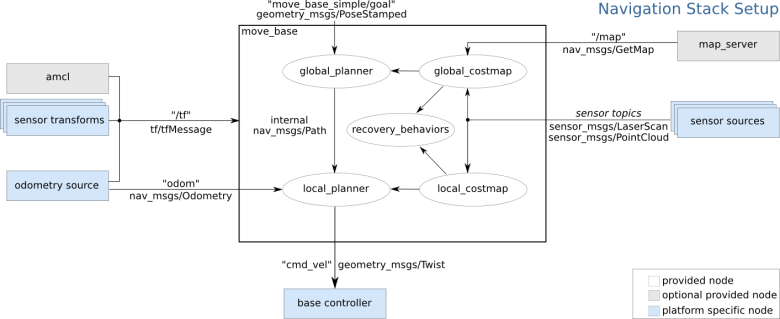
Enter a caption
Looking at the source code directly on the ROS Navigation Github, you can see the source code for the global planning package has multiple source files, one of which is devoted solely for A*. The source script shows the implementation of the AStarExpansion class. The real planner is in AStarExpansion::calculatePotentials(), which will take in a starting pose, an end pose, and then iterate through a potential field and add each node it expands to a queue until the expanded node reaches the goal. If it does not find a goal, it returns back a ‘false’.
bool AStarExpansion::calculatePotentials(unsigned char* costs, double start_x, double start_y, double end_x, double end_y,
int cycles, float* potential) {
queue_.clear();
int start_i = toIndex(start_x, start_y);
queue_.push_back(Index(start_i, 0));
std::fill(potential, potential + ns_, POT_HIGH);
potential[start_i] = 0;
int goal_i = toIndex(end_x, end_y);
int cycle = 0;
while (queue_.size() > 0 && cycle < cycles) {
Index top = queue_[0];
std::pop_heap(queue_.begin(), queue_.end(), greater1());
queue_.pop_back();
int i = top.i;
if (i == goal_i)
return true;
add(costs, potential, potential[i], i + 1, end_x, end_y);
add(costs, potential, potential[i], i - 1, end_x, end_y);
add(costs, potential, potential[i], i + nx_, end_x, end_y);
add(costs, potential, potential[i], i - nx_, end_x, end_y);
cycle++;
}
return false;
}
Example with ROS/Gazebo:
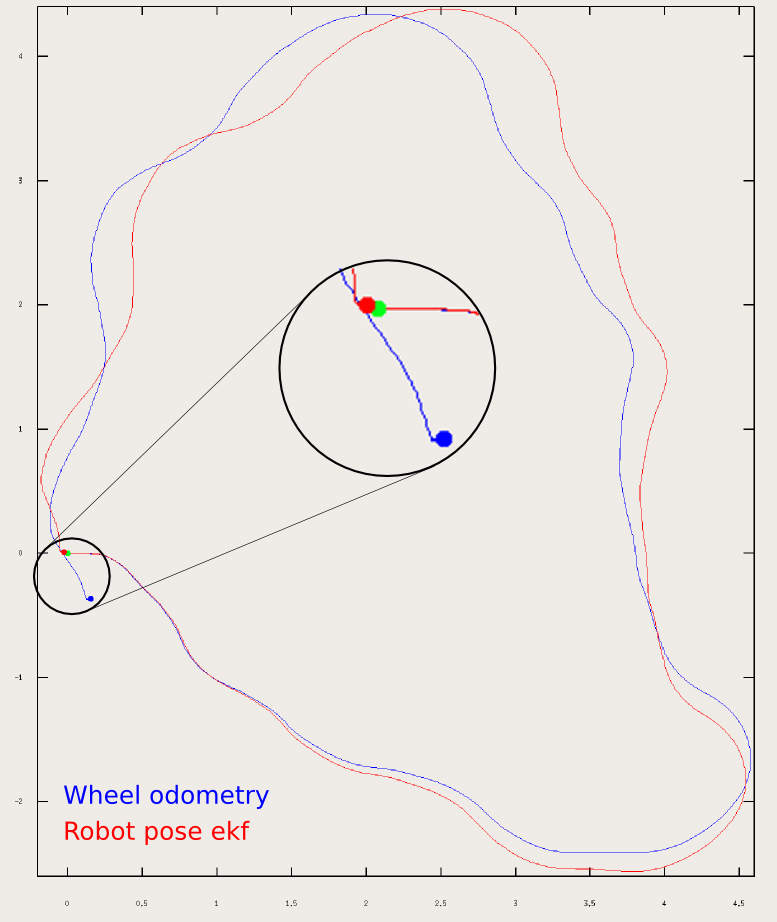
Using our trusty Turtlebot simulator and a previously explored map, we can have Turtlebot plan a global path, then navigate to that goal on the map with a Monte Carlo Localization node to provide a Particle Filter/Estimate of where the robot exists in the map and a controller to actually move the base frame of the robot.
To install the package, we will run:
$ sudo apt-get install ros-[YOURDISTRO]-turtlebot-stage
Then once that is installed, run:
$ rospack profile # Update our ROS package lists to find our new package. $ roslaunch turtlebot_stage turtlebot_in_stage.launch
If everything loads successfully, you should be prompted with an RViz window similar to this:
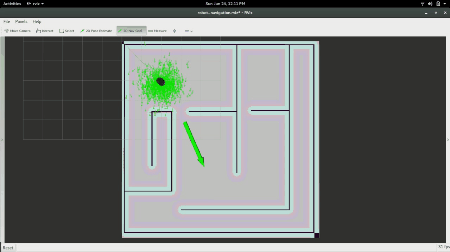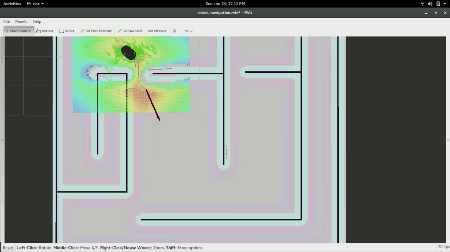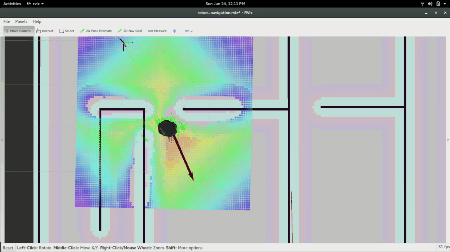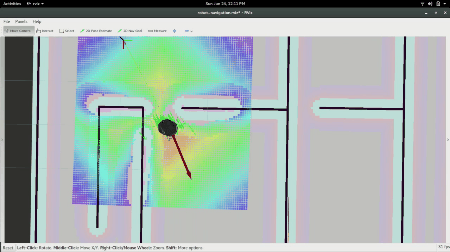
RViz window showing Turtlebot Navigating towards a goal.
In the gif above, you see the robot was given a pose, an (x,y) position in space and an orientation via the red arrow that the local planner and controller are now using. The faint red line is the output of the A* planner and the square grid around it is how the local planner is following the desired trajectory from the global planner.
To give our robot a goal, we will click the button labeled “2D Nav Goal”, and click anywhere on the map, and drag in the direction we want it to have its final orientation. From there, you should see the robot move towards the goal as shown below:
A* is an incredibly powerful algorithm that not only has applications in path planning for mobile robotics but also for general Artificial Intelligence, including the problem of semantic parsing using stochastic grammars in Natural Language Processing! It really makes you appreciate how simple ideas can find usage in world-changing applications.
Until next time, happy robotting!
Liked what you saw? Subscribe for more cool how-tos, side projects, and robot stuff!
Have a comment, issue, or question? Leave a comment or message me on GitHub.








































{kind=link}